
F5 AI Team
Creator
9mo ago
Tips Huấn Luyện LoRA: Hướng Dẫn Chi Tiết Để Bắt Đầu và Tránh Overfitting
Trong thời đại công nghệ hiện nay, việc sử dụng AI để tạo ra các mô hình hình ảnh chất lượng cao đang ngày càng trở nên phổ biến, đặc biệt là với sự ra đời của LoRA (Low-Rank Adaptation) trong mô hình Stable Diffusion & Flux.
Tuy nhiên, không ít người mới bắt đầu cảm thấy bối rối khi đối mặt với việc huấn luyện LoRA và các khái niệm liên quan, đặc biệt là vấn đề overfitting - "quá khớp".
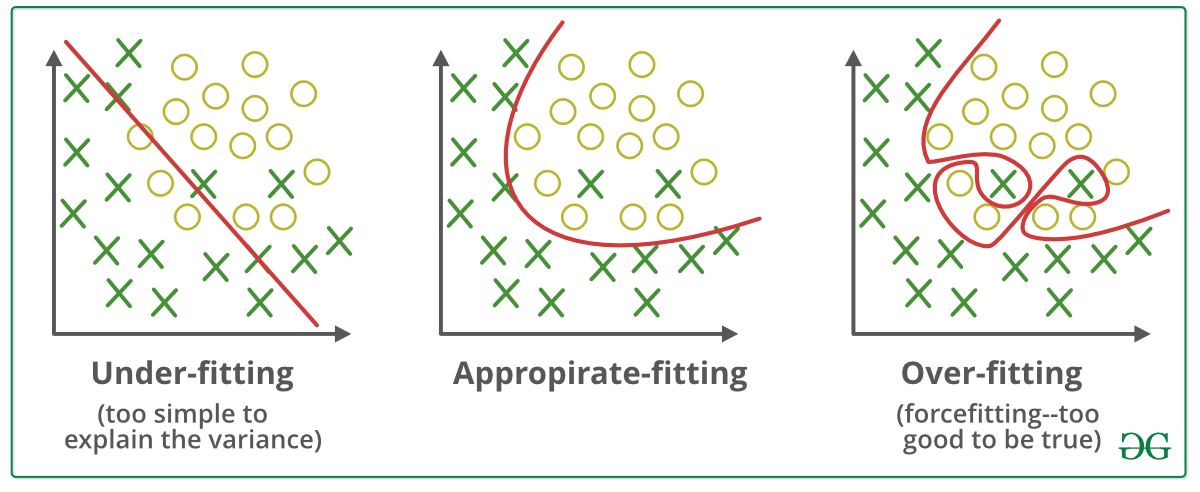
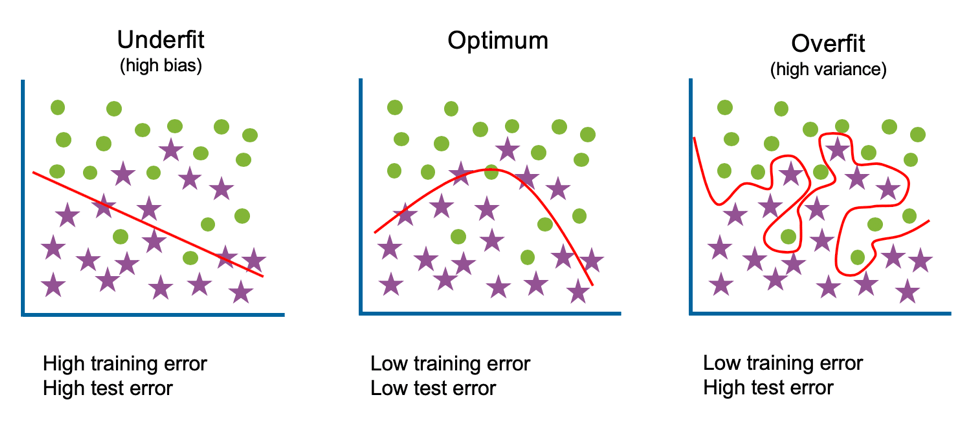
Trong bài viết này, mình sẽ chia sẻ chi tiết về cách bắt đầu huấn luyện LoRA, những điều cần lưu ý và cách để tránh các vấn đề thường gặp.
1. Hiểu Rõ Về Quá Trình Huấn Luyện LoRA
Việc huấn luyện LoRA không chỉ đơn thuần là nạp dữ liệu vào mô hình và chờ đợi kết quả. Mình thường phân tích kỹ các yếu tố sau:
- Tập Dữ Liệu: Số lượng và chất lượng dữ liệu rất quan trọng. Đối với phong cách, mình khuyên nên sử dụng khoảng 20-30 hình ảnh, và cho các nhân vật cụ thể, từ 10-20 hình ảnh. Hình ảnh nên đa dạng để mô hình có thể hiểu rõ hơn về các khái niệm.
- Chú Thích (Captions): Các chú thích giúp mô hình định hình và phân loại dữ liệu. Mình thường sử dụng một tỉ lệ hợp lý: 1/3 chú thích dạng mô tả, 1/3 là danh sách thuộc tính, và 1/3 là từ khóa đơn giản. Điều này giúp mô hình dễ dàng nắm bắt các đặc điểm cần thiết.
2. Vấn Đề Overfitting và Cách Nhận Biết
Overfit xảy ra khi mô hình học tập quá mức từ một tập dữ liệu huấn luyện cụ thể, khiến nó chỉ có thể tạo ra các kết quả tương tự với dữ liệu đầu vào mà không thể mở rộng hay sáng tạo thêm.
Điều này đặc biệt rõ rệt khi huấn luyện LoRA với số lượng hình ảnh ít ỏi hoặc thiếu đa dạng. Thay vì nắm bắt được các đặc điểm tổng quát của nhân vật hoặc cảnh vật, mô hình sẽ chỉ lặp lại các chi tiết đã học.
Dấu hiệu rõ ràng nhất của overfit là khi mô hình tạo ra các hình ảnh với sự lặp lại rõ rệt. Các biểu cảm, pose, hoặc thậm chí chi tiết nhỏ trong ảnh sinh ra từ mô hình sẽ trùng lặp gần như hoàn toàn với dữ liệu huấn luyện ban đầu. Điều này làm giảm tính sáng tạo và linh hoạt của AI, đặc biệt khi áp dụng vào các bối cảnh khác nhau.
3. Nguyên nhân gây ra hiện tượng overfit
Hiện tượng overfit trong quá trình train LoRA có thể xuất phát từ các nguyên nhân sau:
- Số lượng hình ảnh quá ít: Khi sử dụng một tập dữ liệu quá nhỏ, mô hình sẽ không đủ thông tin để học các đặc điểm chung của đối tượng. Điều này dẫn đến việc nó chỉ tập trung vào các chi tiết nhỏ từ dữ liệu ban đầu.
- Thiếu đa dạng trong dữ liệu: Nếu hình ảnh trong tập dữ liệu chỉ tập trung vào một góc chụp, một biểu cảm hay một pose duy nhất, mô hình sẽ "khóa" vào những chi tiết này và không thể tạo ra các biến thể khác.
- Cấu hình không tối ưu: Một số tham số trong quá trình huấn luyện, chẳng hạn như learning rate quá cao hoặc số epoch quá nhiều, cũng có thể khiến mô hình học quá mức từ dữ liệu gốc.
4. Cách hạn chế overfit
Để tránh tình trạng này, mình gợi ý các phương pháp sau:
- Tăng Cường Độ Đa Dạng Dữ Liệu: Sử dụng nhiều hình ảnh khác nhau với nhiều biểu cảm và góc chụp. Đảm bảo rằng bạn có ít nhất 30-50 hình ảnh trong tập huấn luyện để mô hình không chỉ học thuộc lòng mà còn hiểu được bản chất của đối tượng.
- Chọn Lọc Hình Ảnh Chất Lượng Cao: Hình ảnh trong tập dữ liệu cần có độ phân giải tốt và rõ nét. Điều này sẽ giúp mô hình học được những chi tiết quan trọng.
- Điều Chỉnh Tham Số Huấn Luyện: Mới bắt đầu, hãy dùng các tham số mặc định. Điều này giúp bạn dễ dàng xác định nguyên nhân của các vấn đề phát sinh và có thể làm rõ hơn liệu vấn đề có xuất phát từ dữ liệu hay tham số.
- Sử Dụng Kỹ Thuật Early Stopping: Theo dõi kết quả huấn luyện và dừng sớm khi thấy mô hình bắt đầu quá khớp với dữ liệu huấn luyện. Điều này có thể giúp ngăn chặn overfitting trước khi nó xảy ra.
5. Công Cụ Để Huấn Luyện LoRA
Dưới đây là một số công cụ hữu ích cho việc huấn luyện LoRA mà mình đã thử nghiệm hoặc nghe ngóng được:
OPEN SOURCE:
- The Last Ben Runpod: Đây là một công cụ đơn giản và hiệu quả, phù hợp cho người mới. Bạn chỉ cần giữ chú thích ngắn gọn với một token duy nhất và vài từ mô tả.
- Kohya: Cung cấp nhiều tùy chỉnh, tuy nhiên có thể khó cho người mới. Nhưng nó cũng rất mạnh mẽ.
- Fluxgym: Phiên bản dễ dùng hơn dùng lõi là Kohya, có dùng Florence để tạo autocaption, dễ dùng cho người mới
DỊCH VỤ TRẢ PHÍ:
6. Lời Kết
Huấn luyện LoRA là một hành trình thú vị, nhưng cũng đầy thách thức. Để có thể đạt được kết quả tốt, việc nắm vững các yếu tố liên quan đến tập dữ liệu và các tham số huấn luyện là vô cùng quan trọng.
Bên cạnh đó, việc phòng ngừa overfitting và lựa chọn công cụ phù hợp sẽ giúp bạn tối ưu hóa quy trình và tạo ra các mô hình AI chất lượng cao, đa dạng và sáng tạo.
Hãy bắt đầu với các thiết lập mặc định và từ từ khám phá sâu hơn để nâng cao kỹ năng của mình trong việc huấn luyện LoRA.
Chúc bạn thành công trên con đường khám phá thế giới của AI!
This post is part of a community

F5 AI Team
On Facebook
966 Members
Free